


①12月人民币新增贷款或同比少增,市场预测中值为0.77万亿元;
②12月政府债净融资或影响社融读数,市场预测中值为1.74万亿元;
③12月M1增速将维持下降态势,M2增速小幅回落。
技术报告链接:https://arxiv.org/abs/2601.00150

近日,奇富科技联合复旦大学与华南理工大学研究人员共同发布首个面向信贷场景的多模态评测基准FCMBench-V1.0 (Financial Credit Multimodal Benchmarks)。该基准基于真实信贷业务场景,抽象科学问题,设计多模态评估任务与挑战,以期构建来源于业务、服务于业务的实用性评测体系,推动信贷AI的学术研究与应用落地。同时,奇富科技宣布开源数据集与评测工具,为行业共建AI基础设施提供关键支撑。
FCMBench 不仅是当前金融信贷领域样本量最大、最符合真实应用场景的多模态大模型评测基准,更创新推出"感知-推理-鲁棒性"三维评测体系,全面评估信贷AI模型的实战能力。与传统侧重单一识别或理解能力的评测不同,FCMBench所评测出的模型能力,能够直接对应小微企业授信过程中对多证件识别、信息一致性校验与风险线索发现等核心环节,为模型是否具备实际可用性提供清晰、可量化的参考依据。
该基准旨在提供一个标准的评测平台,以促进学术界和产业界之间的协作发展,推动AI更好地赋能信贷场景。一方面,金融机构不再缺乏公平比较信贷领域AI模型能力的标准;另一方面,学术界和金融科技公司的研究人员能够对信贷领域的关键难题开展深入研究。这打破了行业内数据和领域知识壁垒,推动信贷人工智能从“单点优化”迈向“产学研协同创新”。
奇富科技多模态负责人杨叶辉博士介绍:"金融信贷审核涉及几十类证件、每类证件有多种模版、审核流程涉及多个环节和任务、以及多证件的交叉推理验证,用户拍摄的场景和上传的文件也多种多样。信贷场景的这些挑战对于多模态大模型的能力也是非常好的试金石。FCMBench-V1.0 只是一个开始,我们会持续完善这个评测基准,希望打磨好一把公平、公正,面向实战需求的尺子:如果你的模型在FCMBench上取得了好成绩,理论上就可以面向实际落地,而不仅仅是满足了实验室指标。"
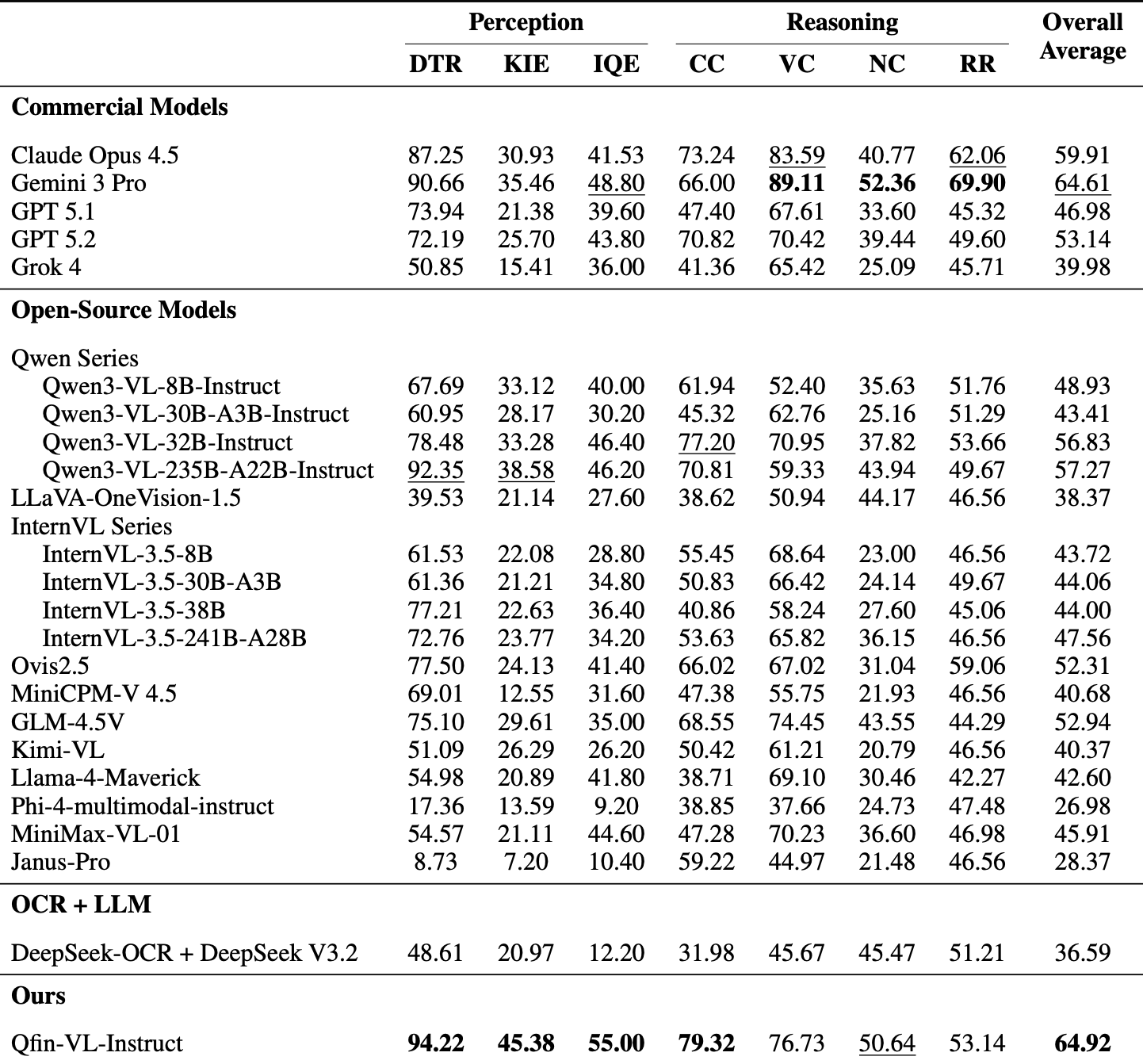
FCMBench-V1.0构建了与真实银行审核流程高度一致的评测框架,涵盖18类核心信贷证件,如身份证、收入证明、银行流水、房产证等,包含4043张合规图像和 8446个测试样本,问题覆盖信贷审核全链条。
其创新的"感知-推理-鲁棒性"三维评测体系,对金融信贷 AI 模型所需的实战核心能力提出了全面的考核。
通过对23个主流多模态模型(来自14家顶尖AI企业及科研机构)的全面评测,FCMBench展现出强大的鉴别能力。结果显示, Google DeepMind的Gemini 3 Pro(64.61)位列商业模型榜首,阿里巴巴Qwen3-VL-235B(57.27)成为最佳的开源基模。而奇富科技自研的信贷垂类多模态大模型Qfin-VL-Instruct以64.92的F1分数斩获综合第一,该模型基于奇富实际业务场景进行研发,彰显了垂类领域定制化训练的优势,该模型的试用接口已向公众开放。
作为该评测基准的核心研究人员,复旦大学与上海创智学院的双聘教授陈涛表示:“FCMBench的发布不仅填补了金融信贷领域多模态评测基准的空白,更构建了金融大模型学术研究与产业应用的沟通桥梁。随着该基准的开源与推广,将吸引更多研究者关注金融AI领域,加速技术创新与落地应用,为行业带来更高效、更可靠的智能解决方案。”
作为该评测基准的主要参与人之一,华南理工大学未来技术学院教授、人工智能与数字经济广东省实验室研究员许言午表示:“通过不断打磨FCMBench 来指引信贷AI模型的开发,不仅有助于推动多模态智能技术在数字金融和实体经济中的安全、合规与高质量应用,也为人工智能与数字经济领域的前沿研究和复合型人才培养提供了重要支撑。希望FCMBench能够加速金融大模型从实验室走向真实业务场景,释放更大的产业价值。”
目前,FCMBench的数据集、评测工具以及Qfin-VL-Instruct的试用接口已开放获取,相关细节已在学术论文中全面披露。奇富科技表示,将持续携手产学研伙伴,推动金融AI技术的标准化与规范化发展,助力金融机构数智化转型与小微企业融资服务能力的持续提升。