
×
①智元机器人和创智学院、香港大学等联合研究团队发布了一项突破性研究成果,系统性地探索了机器人操作学习中数据多样性的三个关键维度; ②研究颠覆了机器人学习领域"数据越多样越好"的传统认知,为构建可扩展的机器人操作系统提供了全新的理论指导和实践路径。

财联社8月6日讯,据“智元机器人”公众号消息,近日,由智元机器人和创智学院、香港大学等联合组成的研究团队发布了一项突破性研究成果,系统性地探索了机器人操作学习中数据多样性的三个关键维度:任务多样性、机器人本体多样性和专家多样性。这项研究颠覆了机器人学习领域"数据越多样越好"的传统认知,为构建可扩展的机器人操作系统提供了全新的理论指导和实践路径。
以下为原文:
智元重磅发布:任务、本体、专家数据多样性的全新认知

近日,由智元机器人和创智学院、香港大学等联合组成的研究团队发布了一项突破性研究成果,系统性地探索了机器人操作学习中数据多样性的三个关键维度:任务多样性、机器人本体多样性和专家多样性。这项研究颠覆了机器人学习领域"数据越多样越好"的传统认知,为构建可扩展的机器人操作系统提供了全新的理论指导和实践路径。
01
任务多样性:
专精 or 博学?数据告诉你答案
在机器人学习领域,一个核心问题一直困扰着研究者:当我们要训练一个机器人模型时,是应该专注于与目标任务高度相关的数据进行"专精"训练,还是应该广泛收集各种任务数据进行"博学"式学习?
为了回答这个问题,我们设计了一个巧妙的对比实验,基于AgiBot World数据集构造了两个规模完全相同但任务分布截然不同的预训练数据集:
▍"专精派"数据集(任务采样)——我们精心挑选了10%与目标任务最相关的任务,这些任务都包含评估所需的五个核心原子技能——抓取(pick)、放置(place)、握持(grasp)、倾倒(pour)和折叠(fold)。如图所示,这种策略虽然技能多样性较低,但高度集中于下游任务所需的技能上。
▍"博学派"数据集(轨迹采样)——从每个任务中随机采样10%的轨迹,完整保留了原始数据集的任务多样性谱。虽然这种方法导致与目标技能直接相关的轨迹更少(59.2% vs 71.1%),但获得了更加均衡的技能分布。
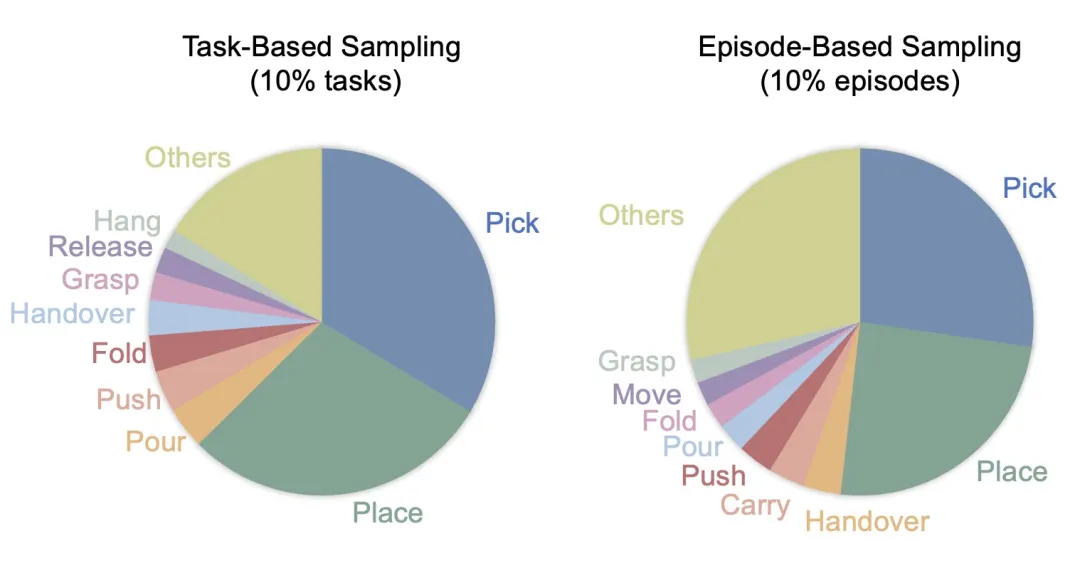
实验结果令人意外!如图所示,"博学派"的分集采样策略在四个挑战性任务上大幅超越"专精派",平均性能提升27%。更值得关注的是,在需要更高语义和空间理解能力的复杂任务上,多样性的优势更加明显——如制作三明治任务提升0.26分(相对提升39%),倒水任务则提升0.14分(相对提升70%)。
为什么多样性会胜出? 我们分析发现,轨迹采样策略不仅带来了技能多样性,而且隐含地包含了更丰富的场景配置、物体变化和环境条件。这种"无心插柳"的多样性也大大增强了模型的泛化能力,让机器人能够更好地适应不同的物体、光照条件和空间布局。
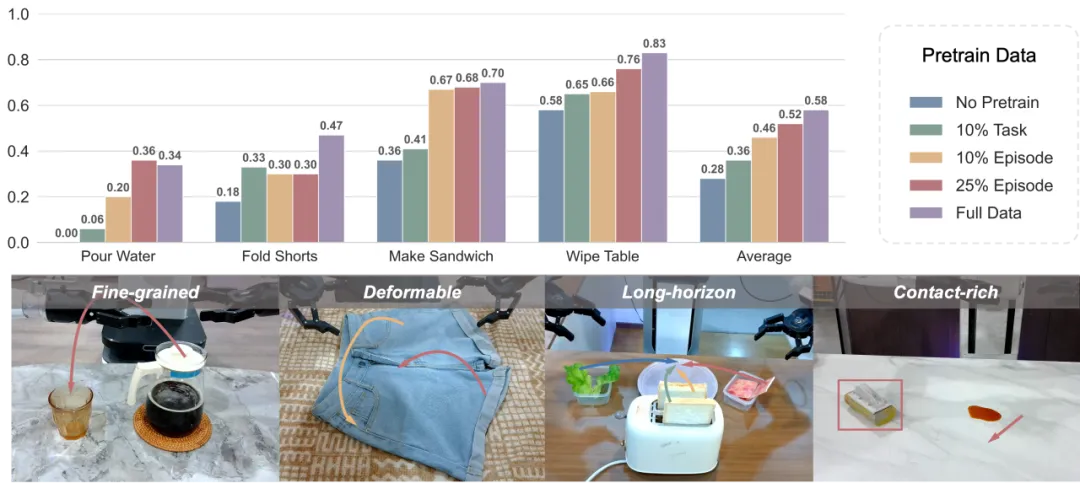
基于"多样性更重要"的发现,我们进一步探索了一个更深层的问题:在保持充分任务多样性的前提下,增加数据量是否还能持续提升性能?实验结果可以发现GO-1模型的平均得分随着预训练数据量的增加呈现出稳定的提升轨迹,更重要的是,这种提升遵循严格的Scaling Law! 通过拟合幂律曲线得到Y = 1.24X^(-0.08),我们发现模型性能与预训练数据量之间存在高度可预测的幂律关系,相关系数达到惊人的-0.99。
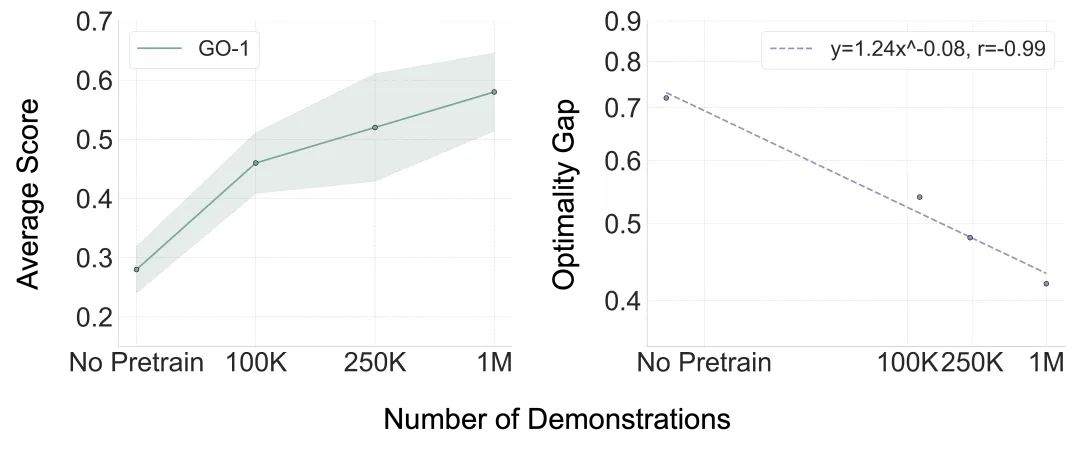
这一发现的重要性不仅在于数值本身,更在于研究范式的重大突破。过去,具身智能领域scaling law研究主要集中在单任务场景、小型模型和无预训练阶段。单任务场景只关注特定任务内的数据扩展,小型模型使用diffusion policy等相对简单的策略网络,无预训练阶段直接在目标任务上训练。本研究将scaling law的探索首次扩展到多任务预训练的foundation model阶段,证明了在保持任务多样性的前提下,大规模预训练数据能够为机器人基础模型提供持续的性能提升,且这种提升是可预测和可量化的。
02
本体多样性:
单一平台数据,实现跨机器人迁移
长期以来,机器人研究社区普遍认为,要让模型具备跨机器人平台的泛化能力,就必须在预训练数据中囊括尽可能多样的机器人本体数据。这一观念催生了像Open X-Embodiment (OXE)这样包含22种不同机器人大规模多本体数据集。
然而,跨本体训练为模型学习带来了诸多困难,不同机器人的物理结构差异巨大,各平台的动作空间和观测空间存在本质差异进一步增加了模型训练的复杂性,面对这些挑战,我们进一步深入思考思考:尽管不同机器人的形态配置千差万别,但它们的末端执行器动作空间在本质上是相似的。当不同形态的机器人让其末端执行器在世界坐标系中遵循相同轨迹时,它们能够产生相当的行为表现。这一观察引出了一个关键假设:在单一机器人本体上预训练的模型,可能能够轻松地将学到的知识迁移到新的机器人配置上,从而规避跨本体训练的复杂性。为了验证这一大胆假设,研究团队设计了一场"以一敌多"的实验对决:
RDT-AWB,基于AgiBot World数据集预训练(100万条轨迹,单一智元精灵G1机器人),完全没有见过目标测试机器人的数据
RDT-OXE,基于OXE数据集预训练(240万条轨迹,22种机器人),包含目标测试机器人的数据,理论上具有"主场优势"
测试环境选择了三个机器人平台:ManiSkill仿真环境的Franka机械臂、RoboTwin仿真环境的Arx机械臂,以及真实世界Agilex环境的Piper机械臂。在ManiSkill环境的跨本体适应实验中,初期阶段RDT-OXE确实表现出"主场优势",在125个样本每任务时略胜一筹。然而转折点出现在250个样本时,RDT-AWB迅速追平RDT-OXE的性能,当数据量继续增加后,RDT-AWB开始反超并持续拉大差距,这种差距增长呈现幂律关系。这一结果表明,单本体预训练模型不仅能够实现有效的跨本体迁移,而且在数据扩展方面表现出更优的scaling特性。
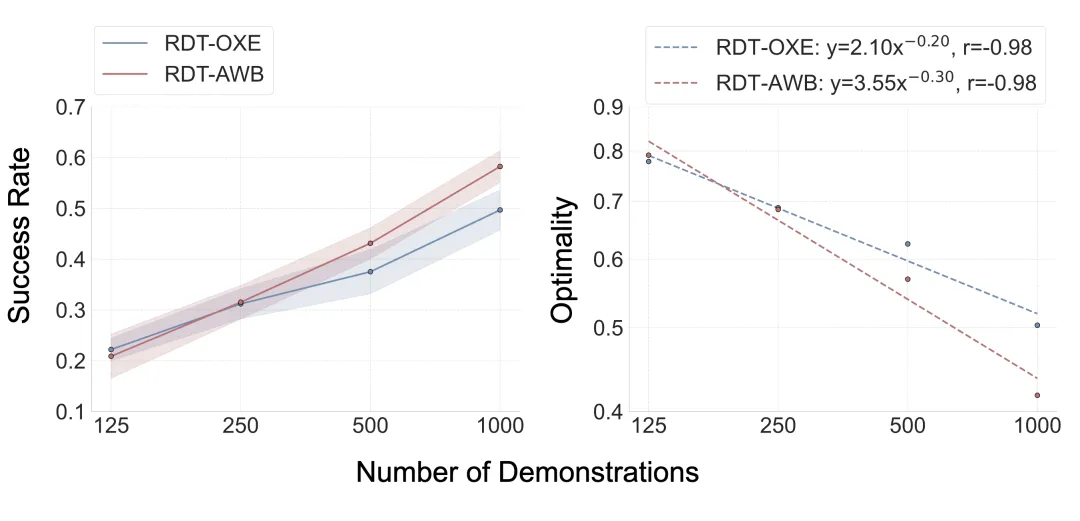
为了确保结论的普适性,在真实世界Agilex环境中,4个任务中的3个任务上RDT-AWB都超越了RDT-OXE,实现了从仿真到现实的全面胜利。
同时我们也在松灵、Franka两个本体上采用叠衣服任务测试了仅在AgiBot World预训练的GO-1模型的跨本体能力,即使预训练数据中没有见过该任务,新本体上也仅需200条数据即可实现模型能力的迁移泛化,GO-1 + AWB相比GO-1 From scratch平均得分提高30%。

这些实验结果具有颠覆性的理论和实践意义。在理论层面,研究证明了跨本体学习的复杂性可能被高估,单本体高质量数据预训练提供了更简洁的技术路径,挑战了"必须多本体训练才能跨本体部署"的传统观念。在实践层面,这一发现能够大幅降低数据收集成本,只需专注于单一机器人平台的高质量数据,同时简化训练流程,为机器人模型的跨平台应用提供了新路径。
03
专家多样性:
识别有害噪声,提升学习效率
在机器人学习中,有一个经常被忽视但至关重要的因素——专家多样性(Expert Diversity)。专家多样性指的是由于不同操作员的习惯、技能水平和固有随机性而产生的演示数据分布变化。与从互联网收集的标准化NLP和CV数据集不同,机器人数据集由连续的机器人运动组成,这些运动对操作员的行为高度敏感。
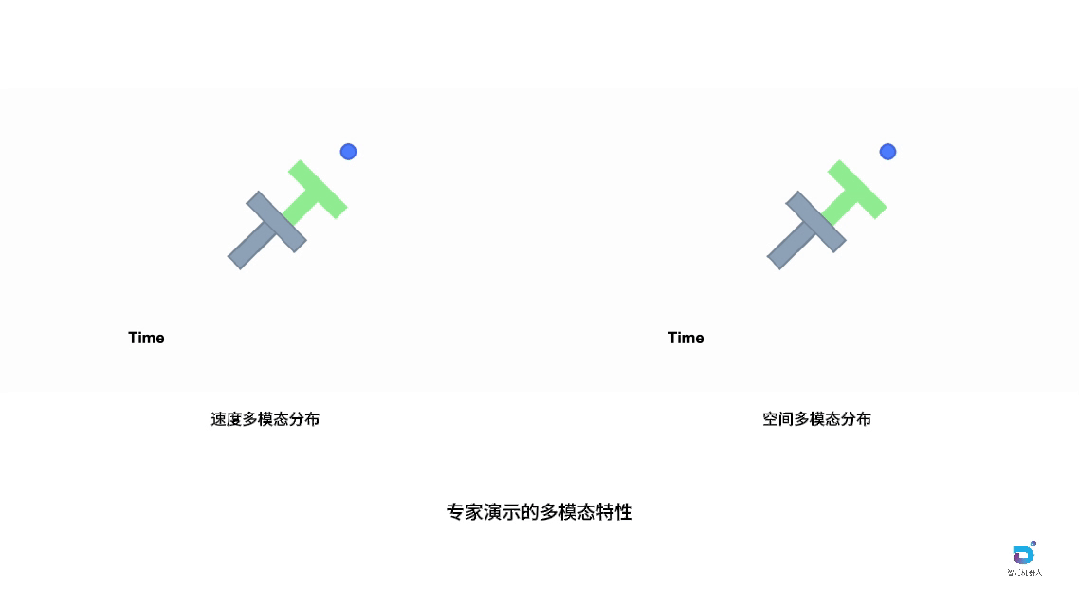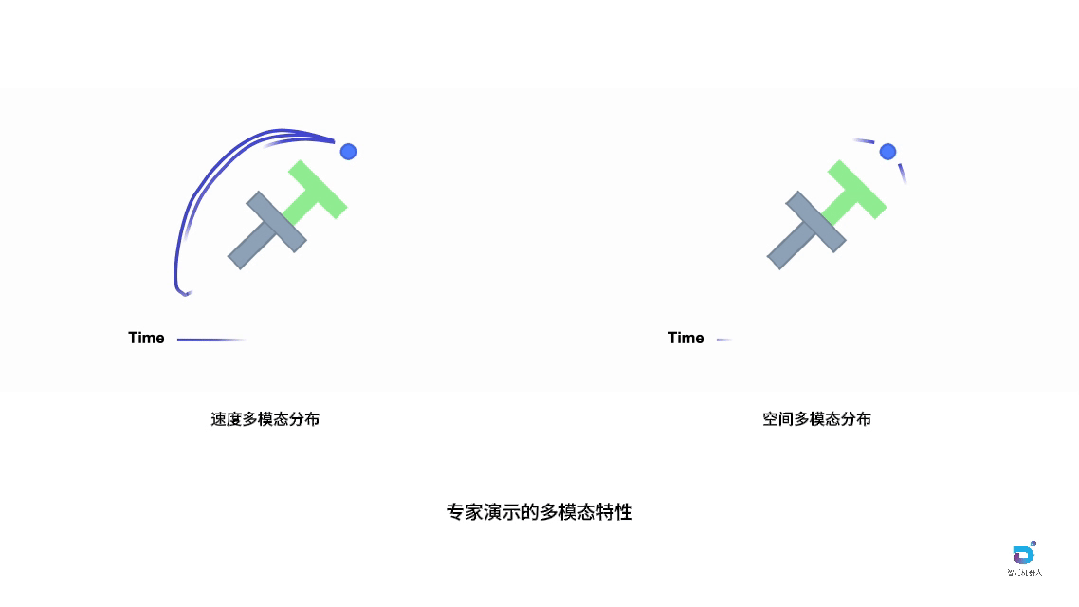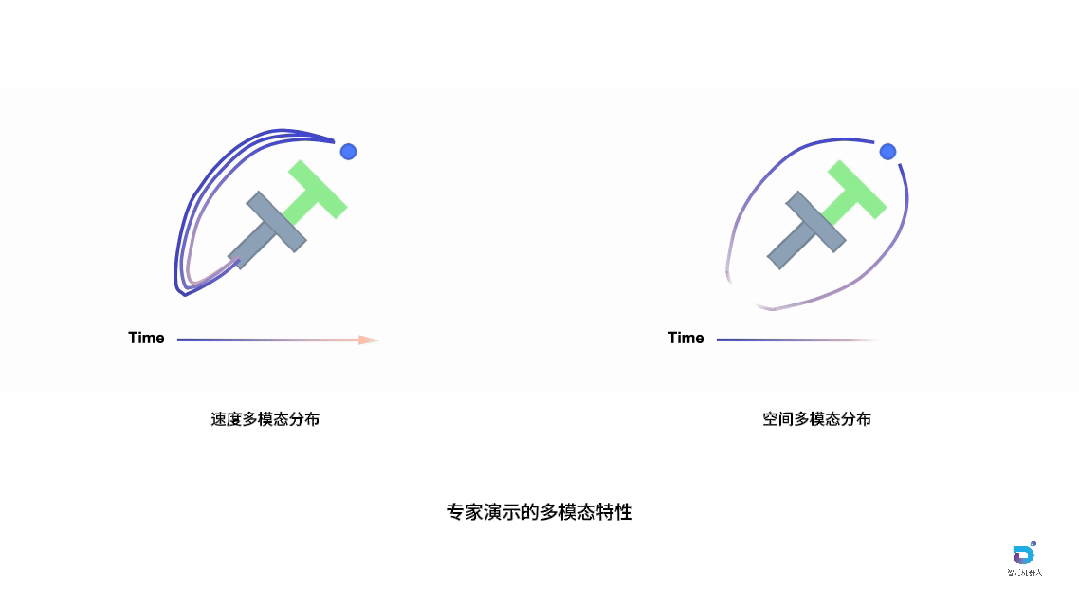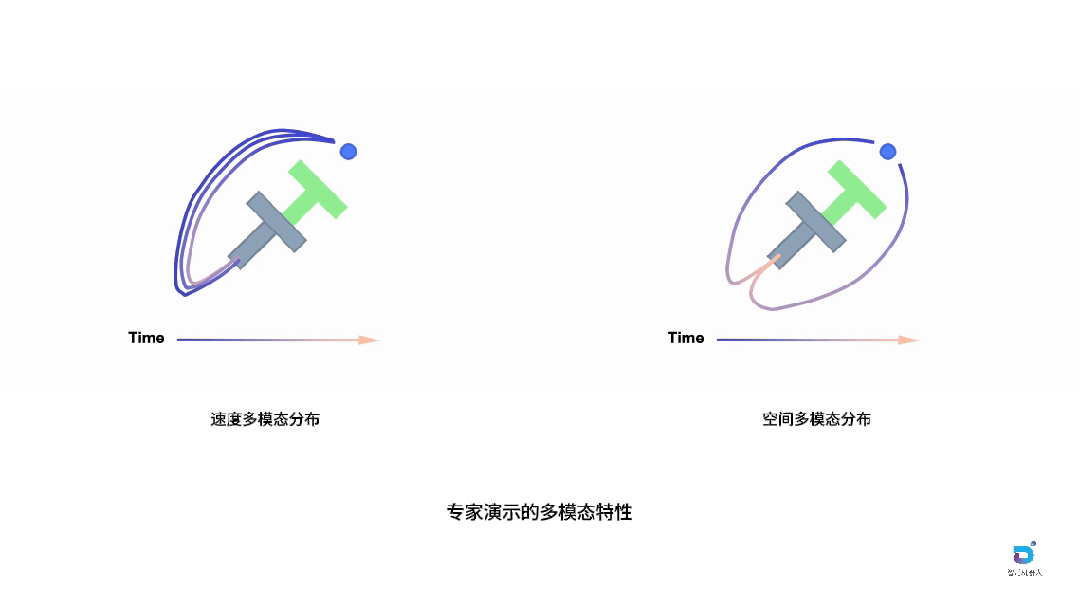
图中通过经典的PushT任务诠释了这一现象。在这个任务中,机器人(蓝色圆圈)需要将灰色的T形物体推动到绿色目标区域。尽管任务目标相同,但采集到的专家演示却表现出明显的多模态特征。空间多模态性体现在不同的轨迹选择上:机器人可以从T形物体的左侧或右侧接近,形成截然不同的空间路径,这反映了操作员对任务策略的不同理解。速度多模态性则发生在机器人以不同速度执行相似轨迹时:即使空间路径相近,不同的执行速度也会在时间维度上产生完全不同的演示轮廓,有些操作员动作迅速果断,有些则相对缓慢谨慎。
这两种多模态性对学习具有完全不同的影响。空间变化代表了有意义的任务策略,这些多样化的解决方案应该被保留,因为它们丰富了模型对任务的理解,囊括更丰富的空间轨迹也可以防止模型推理时超出训练数据分布(OOD, out of distribution)。然而,速度变化往往引入了不必要的噪声,使当前基于动作块的模仿学习变得复杂化,因为模型需要同时学习这些分布特性,增加了学习难度而没有带来实质性的策略价值。
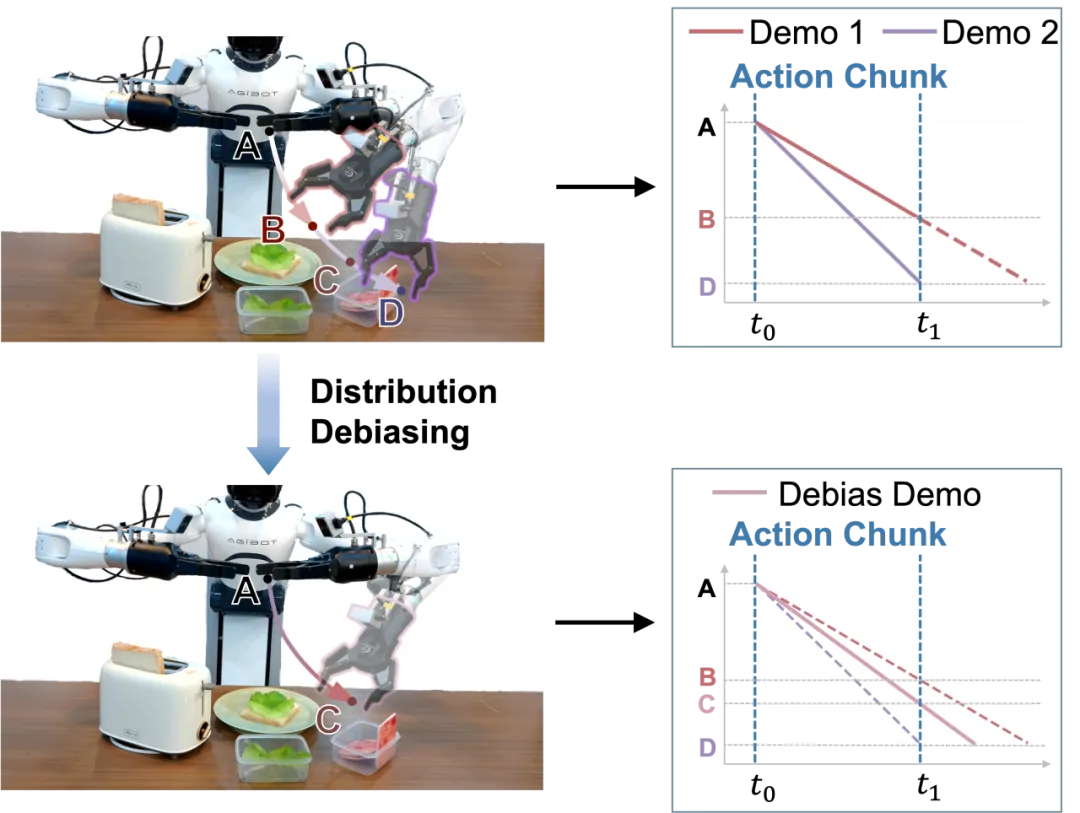
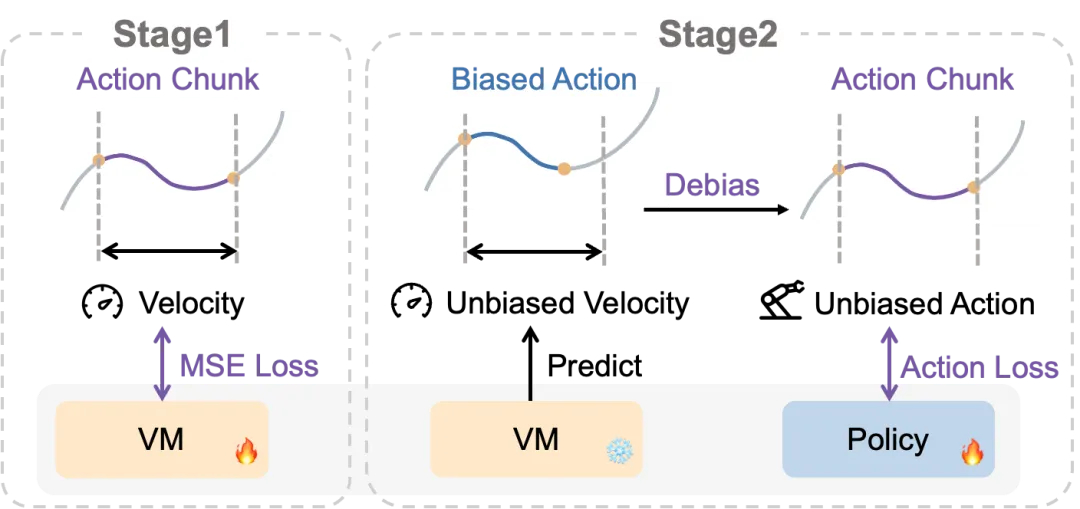
为了解决这一挑战,我们提出了一个巧妙的两阶段分布去偏框架,核心是引入速度模型(Velocity Model, VM)。第一阶段中,VM被训练用于从动作块预测速度,使用MSE损失函数,从带有速度偏差的训练数据中学习每个输入的期望速度。这一阶段让VM掌握了不同动作模式对应的合理速度分布。第二阶段在策略训练过程中,VM首先为每个训练样本预测无偏速度,然后使用这个预测速度将原始动作转换为无偏动作。策略随后使用这些无偏动作作为监督目标进行训练,有效地简化了分布复杂性,让模型能够专注于学习核心的任务策略而不被速度变化所干扰。
我们在擦桌子(Wipe Table)和制作三明治(Make Sandwich)两个代表性任务对分布去偏进行了验证,我们将经过分布去偏数据训练的模型命名为GO-1-Pro,实验结果发现GO-1-Pro在两个任务和所有数据规模上都稳定超越GO-1。值得注意的是,GO-1-Pro展现出卓越的数据效率——仅使用GO-1一半的训练数据就能达到相当或更优的性能,有效地将数据利用效率提升了一倍。
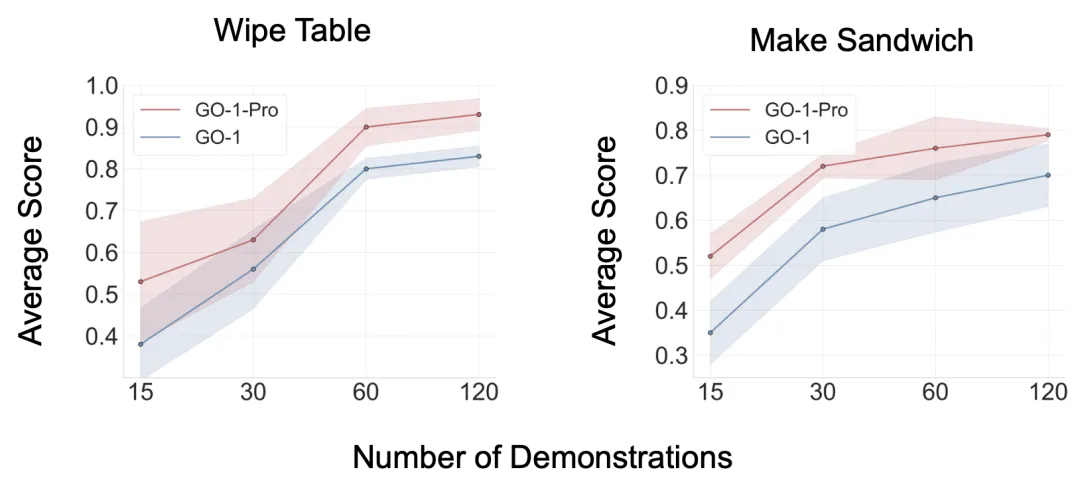
分布去偏方法的优势在低数据场景中尤为突出。在仅有15个演示的数据稀缺条件下,GO-1-Pro将制作三明治任务的性能提升48%,擦桌子任务提升39%。在数据稀缺的情况下,速度和空间维度的多模态分布会在模型学习过程中产生严重干扰,阻碍模型有效捕获核心的空间分布模式。通过解耦这些混淆因素,分布去偏方法使模型能够专注于学习核心空间关系,即使在数据有限的情况下也能实现更高效、更鲁棒的策略学习,为提升模型性能和数据效率提供了一条切实可行的技术路径。
此项研究系统性地探索了机器人操作的数据扩展,揭示了三个颠覆传统认知的关键洞察:任务多样性比单任务演示数量更关键,本地多样性对跨实体迁移并非必需,而专家多样性因速度多模态性可能带来负面影响。这些发现颠覆了"越多样越好"的传统范式,证明了质量胜过数量,精心洞察胜过盲目堆砌——真正的突破不在于收集更多数据,而在于理解数据本质,识别有价值的多样性,消除有害噪声,为机器人学习指明了一条更加高效精准的发展道路。