
×
①M1被定义为“全球首个开源的大规模混合架构推理模型”,原生支持100万Token的上下文窗口,并支持业内最长的8万Token推理输出。 ②当前,大模型的竞争节奏还面临新的变数,那就是——DeepSeek R2的发布。

《科创板日报》6月17日讯(记者 黄心怡) MiniMax行动了。
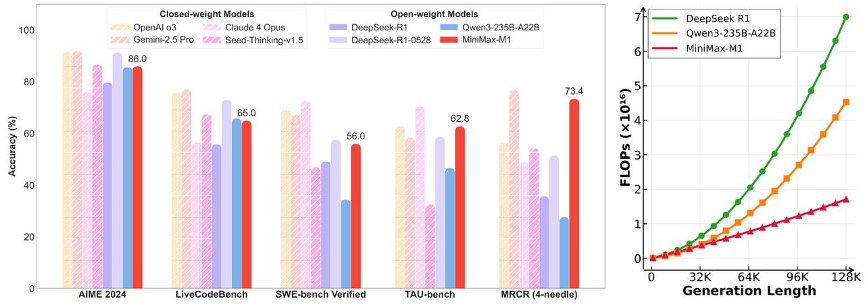
今日凌晨,总部位于上海的AI独角兽企业MiniMax发布其自主研发的MiniMax-M1系列模型。M1被定义为“全球首个开源的大规模混合架构推理模型”。技术报告显示, M1模型原生支持100万Token的上下文窗口,这一数字与谷歌最新的Gemini 2.5 Pro持平,并支持业内最长的8万Token推理输出;其RL(强化训练)成本下降一个量级,成本仅53万美金;在工具使用场景(TAU-bench)中MiniMax-M1-40k超过Gemini-2.5 Pro。
前两个档位的定价均低于DeepSeek-R1,而第三个超长文本档位则是DeepSeek模型目前尚未覆盖的领域。此外,MiniMax方面表示,在其自有的App和Web端,M1模型将保持不限量免费使用。
报告还提到,在进行8万Token的深度推理时,M1所需的算力仅为DeepSeek R1的约30%;生成10万token时,推理算力只需要DeepSeek R1的25%。
MiniMax此次提出的CISPO算法,其收敛性能比字节跳动近期提出的DAPO算法快一倍,也优于DeepSeek早期使用的GRPO算法,这使得M1模型的整个强化学习阶段仅使用了512块英伟达H800 GPU,耗时三周,成本为53.5万美元。MiniMax表示,这一成本“比最初的预期少了一个数量级”。
年初DeepSeek的爆火出圈后,其带来的技术革新与成本降低,拉动了行业“技术平权”,更将压力传到其它大模型厂商,尤其是一路靠风险投资支持,进军到决赛圈的大模型“六小虎”。在DeepSeek影响下,“六小虎”的商业化和融资变得极具挑战。今年以来多家企业出现了联合创始人、高管离职的情况。
为了能够继续留在牌桌上,“六小虎”正在积极破局求变。比如,零一万物在年初调整策略,将大部分训练和AI基础设施团队并入阿里,不再追求训练超级大模型。百川智能则精简B端业务,声称要聚焦AI医疗大模型。
剩下的Kimi、智谱、阶跃星辰选择留在通用人工智能的牌桌上,相继上线了自研推理模型。而MiniMax此次发布并开源推理模型,也预示其做好了准备,将继续加入这场大模型之争中。
《科创板日报》记者获悉,M1的发布是MiniMax“开源周”的序幕。在接下来的四个工作日里,MiniMax计划每天发布一项新的技术或产品更新。
当前,大模型的竞争格局还面临新的变数,那就是——DeepSeek R2的发布。
今年以来,DeepSeek对V3模型和R1模型进行了小版本试升级,但DeepSeek R2模型何时发布,迟迟未有消息。这不仅对DeepSeek自身意义重大,也是现有大模型玩家所面临的一场竞争考验。